
In the last article, we talked about why context engineering matters and how we got here. If you haven't read it, the short version is this: everything we've been doing with prompts, RAG, agents, and MCP was really about one thing, getting the right context to the model. We just never called it that.
Context Engineering 101 - And Why You Should Care
Now let's talk about how to actually do it.
Karpathy defines context engineering as:
"The delicate art and science of filling the context window with just the right information for the next step."
The key phrase here is "just the right information." That's the whole game.
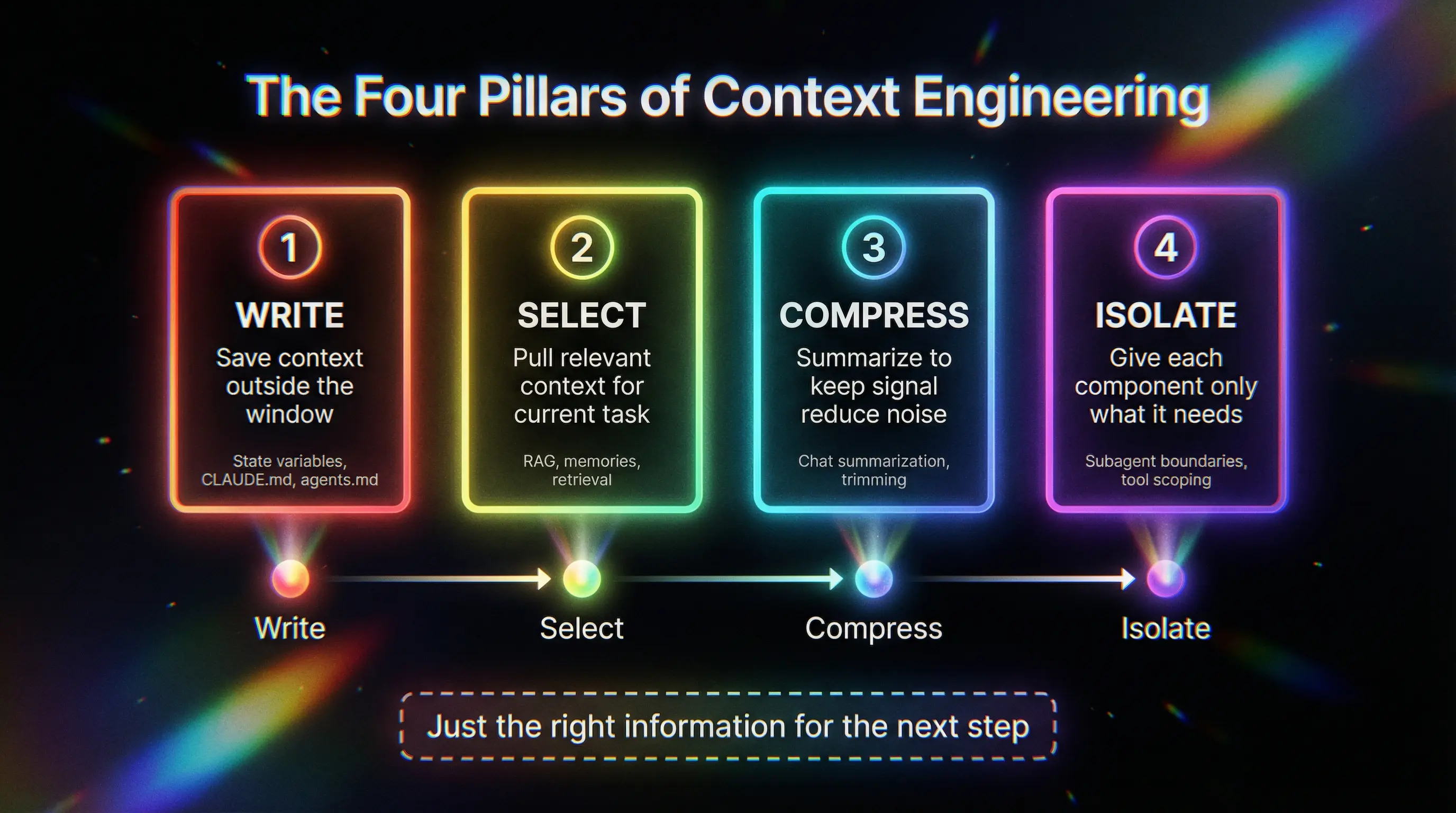
But how do you decide what's "just right"? There's a framework I really like from LangChain that breaks this down into four pillars: Write, Select, Compress, and Isolate. Let me walk you through each one and what they actually mean when you're building.

Write
As your agent runs and conversations grow, you can't keep everything in chat history. That will eat up your tokens fast. The smarter approach is to write important context somewhere outside the context window so it doesn't get trimmed when things get long.
There are two common ways to do this.
The first is state variables, the kind you'd use in LangChain or LangGraph, where you persist information across steps of your agent's execution.
The second is the filesystem. This is where files like CLAUDE.md, cursor.rules, or agents.md come in. You write rules, preferences, and instructions in these files, and they get loaded as global context every time your agent runs. The beauty of this approach is that this context stays protected. It doesn't get summarized or trimmed when you compress chat history to fit the window.
Think of it as giving your agent a reference document it can always access, no matter how long the conversation gets.
Select
Writing context is one thing. Knowing what to pull back in is another.
Select is really about retrieval. When you have a bucket of stored context, whether that's memories, documents, or past interactions, you need to pick what's relevant for the current task.
This is where RAG lives. Without getting into the technicalities of cosine similarity and vector matching, the idea is simple: fetch only what matters right now.
You see this in products like ChatGPT and Claude with their memories feature. Instead of asking "what's your role again?" every time, the system pulls relevant context from stored memories on the fly. The user doesn't notice it, but behind the scenes the right context is being selected and injected.
The risk here is selecting wrong. Pull in irrelevant context and you're not helping the model, you're confusing it. This is where a lot of context poisoning starts, not from bad data, but from good data retrieved at the wrong time.
Compress
When a conversation gets so long that it overflows the context window, something has to give. That's where compression comes in.
The most common approach is summarization. You take the full chat history, summarize it into a condensed block, and keep the last few messages intact so the immediate context stays fresh. The model gets the gist of what happened before without carrying every single token.
But here's the catch: summarization has to be intelligent. If you compress carelessly, you lose critical details and your agent starts making mistakes you can't trace. The accuracy tradeoff is real. Some teams even fine-tune models specifically for summarization at agent boundaries because getting this step wrong cascades into everything downstream.
The goal isn't just to make things smaller. It's to keep what matters while letting go of what doesn't.
Isolate
This one is about protecting the sacred context window from pollution.
Sometimes what's in your context isn't just too much, it's simply not relevant. And irrelevant context doesn't sit quietly, it actively degrades your outputs. This is context poisoning, and isolation is how you prevent it.
The principle is simple: give your LLM or agent only what it needs for the current step. Nothing more.
In a multi-agent setup, when you spawn a subagent, you don't hand over the entire conversation history. You give it just enough context to do its job. When a tool runs, it gets only the inputs it needs to execute. And when a subagent or tool returns a result, you care about the output, not the internal failures or retries that happened along the way. Those details might matter for debugging later, but they don't belong in the orchestrator's context.
Isolation is about being intentional with boundaries. Every piece of context you let in should earn its place.
How It All Connects
These four pillars aren't separate strategies you pick from. They work together.
You write context to preserve what matters long-term. You select from that stored context based on what's relevant now. You compress when things get too long, keeping the signal while reducing the noise. And you isolate to make sure each part of your system only sees what it needs.
When you skip any of these, you end up with bloating. And bloated context doesn't just slow things down, it starts poisoning your outputs with noise you can't trace.
Context engineering isn't about adding more. It's about managing what you have so your agents can actually perform.
References
- Andrej Karpathy on Context Engineering - The tweet that defined the term
- LangChain: Context Engineering for Agents - The Write, Select, Compress, Isolate framework
This Write, Select, Compress, Isolate framework is exactly how we think about context at Chromatic Labs. Every video we generate needs to remember your brand, your product, your creative direction — without bloating the context with irrelevant details. It's the difference between AI that feels coherent and AI that feels random.
Next in the series: Agent Skills, a different way to think about context that changes how you build.





